
On 21 and 30 January 2015, the NewsReader team will organise hackathons in Amsterdam and London, respectively. During these hackathons, participants will get to explore information that was extracted from several millions of news articles about the global automotive industry using the NewsReader pipeline. In this blog post, we’ll explain the technology behind the NewsReader pipeline to give you an idea of the types of information you can find in this dataset.
The data processing pipeline is made up of two main steps: information extraction from the document and cross-document event coreference. The document information extraction pipeline is a typical natural language processing pipeline, where we extract mentions of events, actors and locations from the text. From a sentence such as “The American auto company Chrysler filed for bankruptcy Thursday , however a deal with European auto maker Fiat went through.“, the NLP pipeline will extract things like “Chrysler” and “Fiat” as organisations, “filed” as an event of which “Chrysler” is the agent and “bankruptcy” as the thing that is filed. It also provides links to DBpedia for the entities it finds, thus linking “Chrysler” to “http://dbpedia.org/resource/Chrysler” and “Fiat” to “http://dbpedia.org/resource/Fiat“. Furthermore, it recognises “Thursday” as a temporal expression and relates it to the date the article was published (the article was published on May 1st, 2009, which was a Friday, so Thursday refers to April 30th, 2009). You can try out a small demo of the NLP pipeline yourself here.
During the cross-document event coreference step, the mentions are crystallised into instances, effectively forming a bridge between the document (NLP) and instance (SW) levels. This means that all mentions of Ford and all mentions of Fiat (and all other entities, events and dates etc) are aggregated and represented using RDF and stored in the KnowledgeStore. We link every event or entity instance to the locations in the text files where it is mentioned using the Grounded Annotation Framework. In doing so, we create a database of deduplicated bits of information, that also provides easy access to the various places where the information is presented, allowing users to trace the sources of the information.
The Figure below shows an overview of the pipeline and how information from two news articles is aggregated in the RDF representation.
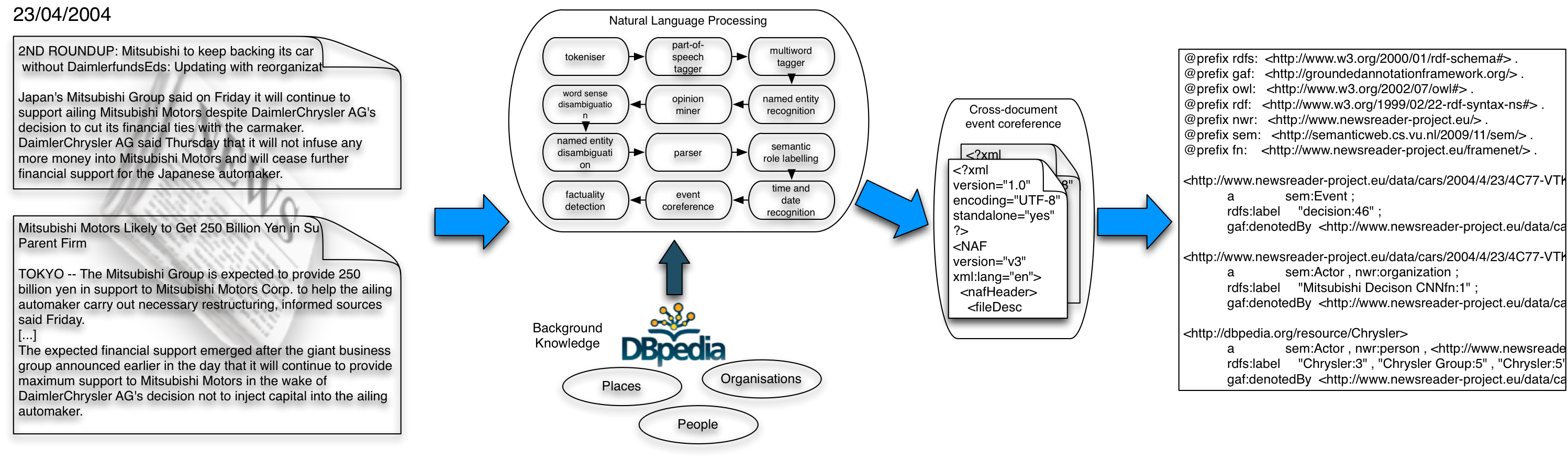
During the hackathon, developers will be able to access the knowledge in the knowledge store through a simple API allowing for easy access. Power users of the NewsReader system will gain access to the information through the SynerScope tool or directly through the KnowledgeStore, which allows users to access the data through SPARQL and CRUD queries.
If you want to join our automotive Hack Day then you can sign up for the Amsterdam event here or for our London event here.