
On this page, we will publish datasets made available through the NewsReader project. Data are listed in historical order. You will find the most recent data down the list.
The following datasets are currently available:
- Global Automotive Industry, automatically extracted Events 2003-2013
- CrunchBase RDF
- TechCrunch, automatically extracted events June 2005 – August 2013
- The ECB+ corpus
- FIFA World Cup
- The NewsReader MEANTIME Corpus
- English Wikinews articles up to April 2013, fully processed by NewsReader pipeline v2.1
- English Wikinews articles up to November 2015, fully processed by NewsReader pipeline v3.0
- Italian Wikinews articles up to October 2015, fully processed by the Italian NewsReader pipeline
Detailed descriptions of the datasets:
1. Global Automotive Industry, automatically extracted Events 2003-2013
Batch 1 (processed in 2013)
64,540 English news articles about the Global Automotive Industry were processed using the first version of the NewsReader NLP Pipeline (as described in Deliverable D2.1) and the resulting text mentions were aggregated into event instances (see Deliverable D5.1.1).
The dataset contains over 1 million extracted events, with their participants and locations. The data contains links to DBpedia for entities and provenance information as to in what source the event was mentioned. The data is in TriG format.
The data can be downloaded as a single zip file here (381MB)
Batch 2 (processed in 2014)
In 2014, 1.3 million news articles about the Global Automotive Industry were processed using the second version of the NewsReader NLP Pipeline (as described in Deliverable D2.2) with the resulting text mentions aggregated into event instances as in Batch 1. In addition, the processing in this dataset also contains some domain specific modules, which are described in Deliverable D5.2.1.
The dataset contains 1.8 million entity instances (compressed from 54 million entity mentions) and 19 million event instances (referred to through 100 million event mentions). Where possible the data is linked to DBpedia instances. Furthermore, event information is linked to the Events and Situations Ontology.
The dataset is split into two TRiG files:
- Contextual events (4.3GB)
- Grammatical events (745MB)
CrunchBase.com is a database that contains all types of information about the tech startup world such as who invested in what company and how much funding a company received. CrunchBase is hosted by TechCrunch, but the contents can be edited by anyone as it is set up as a wiki.
We have gathered the following entities from CrunchBase on August 19, 2013:
| Entity | Number | % |
| Company | 183,184 | 47.32 |
| Person | 183,184 | 47,32 |
| Financial Organisation | 10,006 | 2.58 |
| Service Provider | 6,238 | 1.61 |
| Product | 25,754 | 6.65 |
| Total | 387,097 | 100 |
Acquisitions, competitions, investments, providerships, relationships and products are encoded as typed relations between entities. The CrunchBase data was downloaded through the REST API and converted to RDF (see Deliverable D4.3.1 for details). CrunchBase’s content is available under the Creative Commons Attribution License (CC-BY). The only requirement is that there is a link back to CrunchBase from any page that uses CrunchBase data.
This dataset is available in JSON and can be downloaded in parts:
3. TechCrunch, automatically extracted events June 2005 – August 2013
TechCrunch.com is an English language news website dedicated to the tech world. ScraperWiki downloaded the 43,384 articles that were available on the site on August 15, 2013. We ran the articles through the second version of the NLP pipeline (as described in Deliverable D2.1) and the resulting text mentions were aggregated into event instances (see Deliverable D5.1.1).
This dataset is available in TriG format in two versions:
1. Clustered by topic and publication month (283M)
2. Unclustered (68M)
The ECB corpus was extended with more documents within topics to obtain more referential ambiguity. For example, if the original ECB corpus includes a topic with news articles on an election, then we added new documents with news on another election to this topic. The documents are annotated with events, their participants, time and place to evaluate coreference for events. For more details and data download click here.
A dataset consisting of 300,000 English language articles from LexisNexis dating from January 2004 to April 2014 as well as content scraped from the BBC and Guardian websites by ScraperWiki related to the Football World Cup was compiled for the June 2014 Hackathon.
The articles were processed using the NewsReader NLP pipeline version 1 and yielded 72M mentions, and 136M triples extracted from news); in addition, 105M triples from background knowledge (DBpedia 3.9).
The dataset is split into three TRiG files:
- Contextual events (2.6GB)
- Grammatical events (498MB)
- Source events (396MB)
6. The NewsReader MEANTIME Corpus
The NewsReader MEANTIME (Multilingual Event ANd TIME) corpus is a semantically annotated corpus of 480 English, Italian, Spanish, and Dutch news articles.
For more details and data download go to http://www.newsreader-project.eu/results/data/wikinews/
7. English Wikinews articles up to April 2013, fully processed by NewsReader
For this data set, we show the 3 main steps of processing in NewsReader: Natural Language Processing to create so-called NAF files with annotations of the text, semantic modeling to create RDF-TRiG representation according to GAF-SEM from the NAF files and storage of the RDF-TRiG in the KnowledgeStore to support SPARQL request and reasoning.
A dump of the English Wikinews was processed by the NewsReader pipeline version 2.1, dd 20150218. This generated 18,513 NAF files containing 12 annotation layers from 15 different NLP modules, as shown in the next two images:


You can download the NAF files here:
annotated_NAF_enwiki_20150218_1.tar (237MB)
annotated_NAF_enwiki_20150218_2.tar (492MB)
Next, we used the NAF2SEM program to obtain an RDF-TRiG representation of the NAF files according to the GAF-SEM model. Whereas in NAF, we annotate entities and events as they are mentioned in the text, in GAF-SEM we represent entities and events as instances with pointers to their mentions in the text. That means, every entity and event instance gets a unique URI. The same holds for relations between entities and events, according to the named graph paradigm. Provenance statements are then expressed as triples between mentions in texts and entity/event URIs or between mentions and the URIs (named graphs) expressing relations between entities and events.
The URIs for entities are either based on DBPedia identifiers, if recovered, or created as blank URIs in case we could not match them. Below, we show two entities, Panama matched with DBpedia and Escondido_City_Council that was not matched:
<http://dbpedia.org/resource/Panama>
rdfs:label “Panama Canal” , “Panama” ;
gaf:denotedBy <http://en.wikinews.org/wiki/Frog-killing_fungus_spreads_across_Panama_Canal_towards_South_America#char=258,264> , <http://en.wikinews.org/wiki/Frog-killing_fungus_spreads_across_Panama_Canal_towards_South_America#char=285,297> .
<http://www.newsreader-project.eu/data/cars/entities/Escondido_City_Council>
a nwrontology:ORGANIZATION ;
rdfs:label “Escondido City Council” ;
gaf:denotedBy <http://en.wikinews.org/wiki/Chula_Vista,_California_becomes_model_for_blight_control_laws_in_the_US#char=842,864> .
For events, we create blank URIs to represent an instance that can be mentioned in different places possibly across different articles:
<http://en.wikinews.org/wiki/Passenger_plane_crashes_in_Nepal_killing_18#ev12>
a sem:Event , fn:Killing , eso:Killing , <http://www.newsreader-project.eu/ontologies/wordnet3.0/ili-30-01323958-v> , <http://www.newsreader-project.eu/ontologies/wordnet3.0/ili-30-01325536-v> , <http://www.newsreader-project.eu/ontologies/wordnet3.0/ili-30-01325774-v> , <http://www.newsreader-project.eu/ontologies/wordnet3.0/ili-30-02748495-v> , fn:Cause_to_end , nwrontology:GRAMMATICAL , <http://www.newsreader-project.eu/ontologies/wordnet3.0/ili-30-00352826-v> , <http://www.newsreader-project.eu/ontologies/wordnet3.0/ili-30-01620854-v> ;
rdfs:label “suffer” , “kill” , “end” ;
gaf:denotedBy <http://en.wikinews.org/wiki/Passenger_plane_crashes_in_Nepal_killing_18#char=87,94> , <http://en.wikinews.org/wiki/Passenger_plane_crashes_in_Nepal_killing_18#char=134,140> , <http://en.wikinews.org/wiki/Passenger_plane_crashes_in_Nepal_killing_18#char=544,547> , <http://en.wikinews.org/wiki/Passenger_plane_crashes_in_Nepal_killing_18#char=1205,1214> .
For determining event-coreference, the fact that two mentions in the text point to the same event, we divide the events in 3 categories based on the FrameNet frame associated with the events:
- source events: events that take as an argument the source of information, such as say, tell, think, believe.
- grammatical events: events that express properties of other events, such as begin, start, end, stop.
- contextual events: all other events that tell you something about what happened in the world.
Note that some events may belong to multiple categories, in which case we prefer the contextual interpretations. Further note that the above division in FrameNet frames is based on the dominant interpretation in the automotive industry data set and has not been adapted to the Wikinews data.
For events to be co-referential, they need to belong to the same type, be associated to the same point in time and share an entity as a participant. All the RDF-TRiG data is divided over separate sem.trig files according to the above criteria. This means that entities with the same URI can occur in different em.trig files but that events are unique within each sem.trig file. You can download the sem.trig files in separate batches according to their type from here:
- contextual sem.trig files (75MB)
- source sem.trig files (39MB)
- grammatical sem.trig files (22MB)
As the last step, the sem.trig files have been loaded into the KnowledgeStore, through a knowledge population process. The Wikinews KnowledgeStore access point can be found here:
- 18,510 news articles (18,509 linked in the trig files),
- 2,629,176 mentions (2,600,535 linked in the trig files)
- 9,665,483 triples created by the NAF2SEM module
- 35,102 triple from ESO reasoner
- 95,910,378 from DBpedia 2014
8. English Wikinews articles up to November 2015, fully processed by NewsReader pipeline v3.0
A dump of the English Wikinews was processed by the NewsReader pipeline version 3.0, dd 20150218. This generated 19,757 NAF files containing 13 annotation layers from 17 different NLP modules, as shown in the next two images:

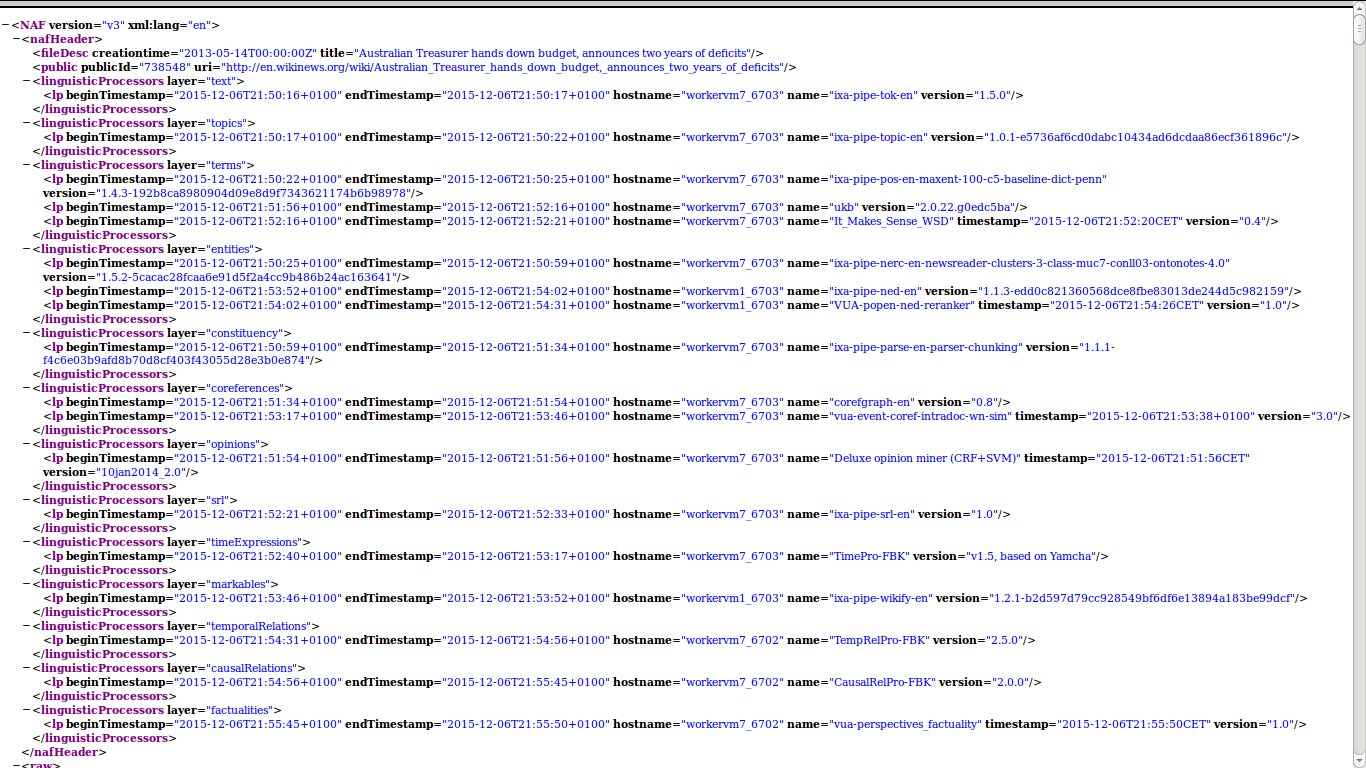
You can download the NAF files here:
NAF_enwiki-20151102_out_uriclean.tar.gz (753MB)
9. Italian Wikinews articles up to October 2015, fully processed by the Italian NewsReader pipeline
A dump of the Italian Wikinews (https://it.wikinews.org/wiki/) was processed by the Italian NewsReader pipeline. This generated 6,430 NAF files containing 10 annotation layers from 13 different NLP modules.
You can download the NAF files here: