1 Overview
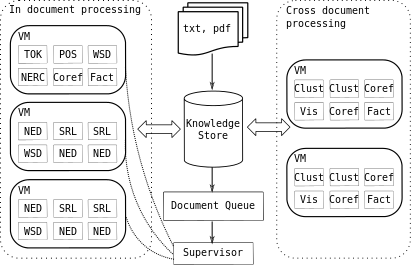
The NewsReader architecture is shown in the image below. The architecture consists of several building blocks: NLP modules, a central repository (the KnowledgeStore) and a visualization component (a Decision Support module). General NLP components are shown as rectangular boxes, rounded by dotted lines. The KnowledgeStore is placed at the center of the image, showing its central role on the whole process. The visualization component is represented by a red circle at the bottom left of the picture.
The workflow of the NewsReader architecture is the following:
- Incoming documents are stored in the KnowledgeStore using its API for document population.
- Linguistic processing of the document is then triggered. The processing comprises two stages: inter-document analysis and cross document analysis.
- The knowledge extracted as a result of the linguistic analysis is send to the KnowledgeStore, which merges and integrates it with the knowledge acquired so far.
- The events and story-lines are visualized by the Decision Support module.
2 NewsReader pipeline for Big Data
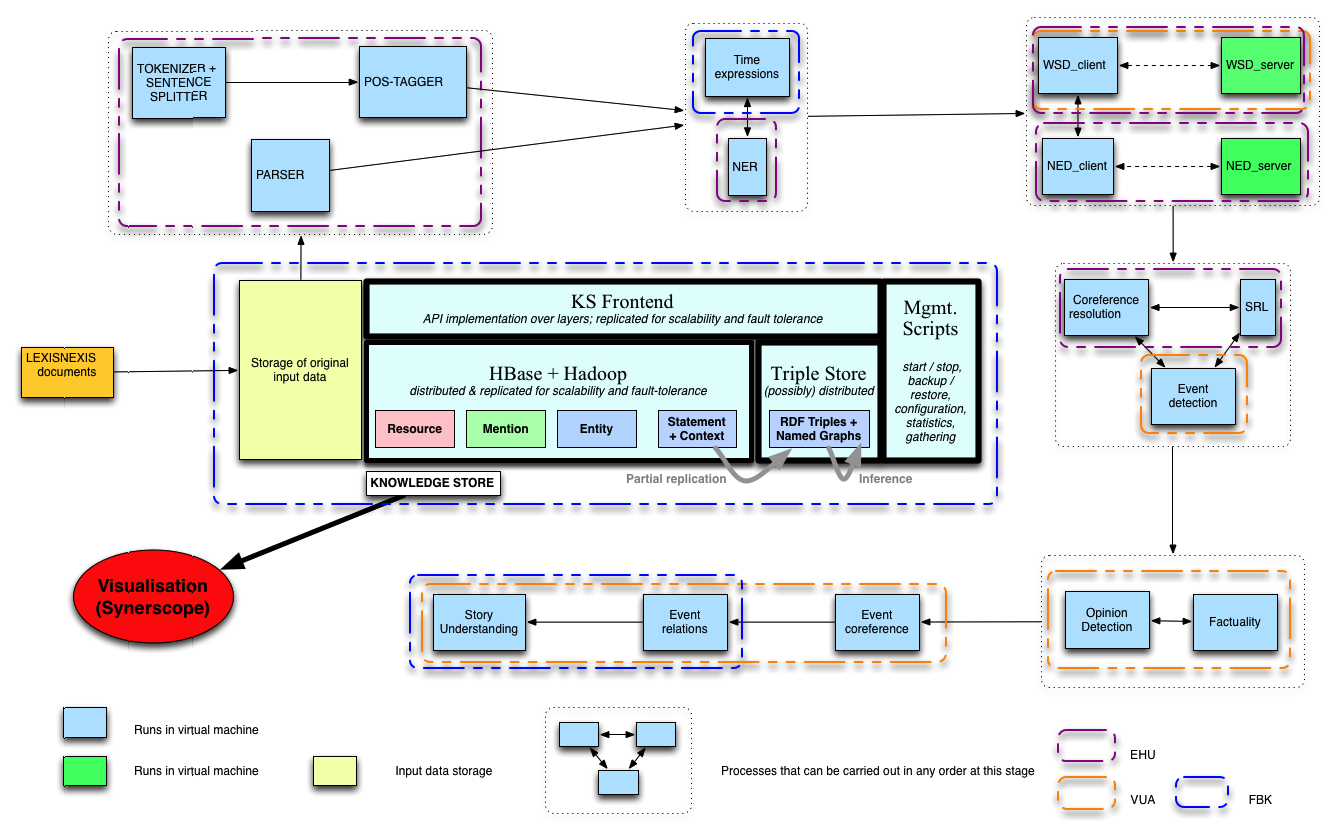
The linguistic processing is performed by a series of NLP modules running sequentially. The modules consume and produce the linguistic annotations following a common representation format, called NAF (NLP Annotation Format). NLP modules of each language are packed into virtual machines, and deployed in several servers among the partners.
Inside each VM the modules are managed using the Storm framework for streaming computing. Using Storm, we implement a topology (a graph of computations) which describe the processing stages each document undergo.
In the first year of the project we scale out our solution for NLP processing by deploying all NLP modules into VMs and making as many copies of the VMs as necessary to process an initial document batch of documents on time. This is shown in the following figure:
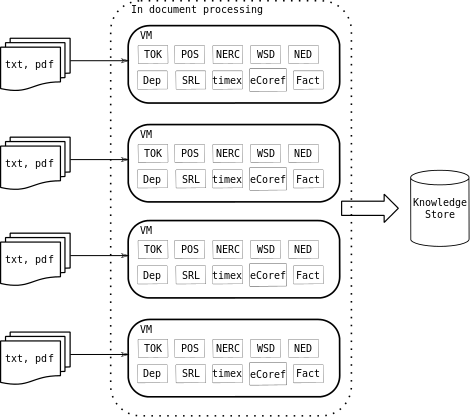
For the second year of the project, we will implement a streaming architecture whis is capable of dealing with the continuous processing of streams of documents reaching at any time. Unlike the approach described in the section above, where a document is completely analyzed inside a single VM, this setting allows distributed processing of documents into several VMs. That is, different stages of the pipeline a document undergoes are actually executed on different machines. This approach allows multiple copies of LP modules running inside a specialized VMs or even dynamically increasing the computing power for the LP modules which require more computational resources.