
Within the NewsReader, many different pieces of technology come together. On this page, we give an overview of the different parts that make up the system and a short intro on how to use them. To get an idea of the types of things you could do, you can find some examples of our previous hackathons here and here.
Data Dumps:
These data dumps were created for the Y3 end user evaluation during which we asked the questions given in this document. This may give you some inspiration for the kind of information that is in here.
We have made available a few CSV files: https://www.wetransfer.com/downloads/15783a898a29303253afeba4257a56c120151125112443/ed0c879fc2788c4b83a9ca0243f022d320151125112443/ce86fa For questions about this dataset, ask Tessel.
They contain the following:
- Takata_events: contains events in which Takata is involved
- Takata_entities: contains other entities (companies, people etc) who are involved in those events
- FCA_events: contains events in which FCA is involved.
- FCA_entities: contains other entities (companies, people etc) who are involved in those events
- Tesla_events: contains events in which Tesla, Fisker and Elon Musk are involved.
- Tesla_entities: contains other entities (companies, people etc) who are involved in those events
The filenames point to files in the LexisNexis database that you can retrieve with credentials you find on the tables.
Main access points
Most developers will probably be familiar with web APIs. The NewsReader API, including documentation, can be found at https://newsreader.scraperwiki.com/
We also have a small slideshow that highlights some of the APIs features here.
The API is actually a front-end to our main graph database, the KnowledgeStore. On the KnowledgeStore website you can find the documentation and access options. We have posted a short video demo’ing the KnowledgeStore on YouTube.
Data: text level and instance level
The data in the KnowledgeStore is a mix of data extracted from text (via Natural Language Processing, or NLP, methods) and structured Semantic Web data. But all resulting data is represented using RDF (Semantic Web format). This means that all data is stored as triples, meaning there is a subject, a predicate and an object. Each triple can be read like a simple fact, for example “Ford manufactures cars”, but then each element is linked either to a resource. For an intro to RDF, check out http://www.seoskeptic.com/web-3-0-101-semantic-web-resources-beginner/
The texts that were processed for the NewsReader project come from the LexisNexis database and consist of news articles pertaining to the global automotive industry. For this hackathon, we have processed news articles that were published between January 2003 and September 2015.
In the NewsReader project, our main focus is the extraction and linking of events. Therefore you will find events that can be recognised by their “ev” Id at the end of the URI. An example of an event URI is:
http://www.newsreader-project.eu/data/cars/2013/04/29/589J-S3N1-JBV1-X31S.xml#ev17
Events have participants, times and take place at certain locations. We represent actor information through the sem:hasActor property. Where ‘sem’ refers to the Simple Event Model, this is a conceptual model that tells the computer (and us) what an event is and what kind of things can be linked to it.
| http://www.newsreader-project.eu/data/cars/2013/04/29/589J-S3N1-JBV1-X31S.xml#ev17 | http://semanticweb.cs.vu.nl/2009/11/sem/hasActor | dbpedia:Martin_Winterkorn |
Similarly, sem:hasTime tells us the data of the event:
One important element that sets the NewsReader datasets apart from most other RDF datasets is the linking to the original text mentions. We know that in our dataset certain people like Martin Winterkorn are mentioned many times, but all those mentions refer to one and the same person. We treat DBpedia (a structured version of Wikipedia) as our description of the ‘real world’ in which there is only one Martin Winterkorn who is the current CEO of Volkswagen AG and who was born on 1947-05-24 (see for example http://dbpedia.org/page/Martin_Winterkorn and http://en.wikipedia.org/wiki/Martin_Winterkorn to find out what kind of information is included in DBpedia from Wikipedia).
In the NewsReader dataset, we use the grounded annotation framework, to create links between those text mentions (identified by the article ID and the character offset) and the ‘things’ they refer to (a DBpedia link or a link to an instance in our dataset). An example of Martin Winterkorn being mentioned in a particular article would thus look like:
| dbpedia:Martin_Winterkorn | gaf:denotedBy | http://www.newsreader-project.eu/data/cars/2013/04/29/589J-S3N1-JBV1-X31S.xml#char=312,329 |
Data enrichments
Furthermore, we don’t just extract participants, locations, and times for the events, but we also link the predicates to richer sources so we can generalise over the words that are used to the concepts (we are basically explicitly telling the computer that leasing and renting are similar concepts). This is done through the Events and Situations Ontology (ESO) You can find a short overview of the ESO in this handout. An overview of the ESO classes can be found in this document.
As we take events as ‘things that happen’ the ESO elements are linked to the predicates in the RDF. For example:
| http://www.newsreader-project.eu/data/cars/2013/02/26/57VK-J831-F091-R2TK.xml#ev35 | eso:possession-owner_1 | dbpedia:Martin_Winterkorn |
Here there is an event where there is some change of possession, and http://www.newsreader-project.eu/domain-ontology/#ChangeOfPossession tells us that Martin Winterkorn is the event’s “Agent,Donor,Exporter,Lender,Seller,Sender,Source,Supplier,Victim” indicating that in this particular event is he not gaining any possessions (in fact, the text states that he will receive 17 percent less compensation).
The KnowledgeStore also contains the DBpedia background information, so it also tells us that Martin_Winterkorn is a Person and that Volkswagen_AG is a Company.
We have precompiled some statistics on the dataset that may be useful to you. You can find them in this Google Spreadsheet.
Precompiled CSVs:
We have precompiled some CSV files for queries that we think may be useful to many of you. You can find those here.
Pilot dataset: NewsReader perspectives dataset
The perspective dataset provides additional information about the data we extract. In particular, it indicates the source of information, their certainty, whether they confirm or deny something and whether they talk about established events or events that will occur in the future.
We explained above that the KnowledgeStore contains an aggregated representation of information we extracted from the news. All events, persons, locations and relations between them are linked back to the place or places in text where they were mentioned through the grounded annotation framework.
The perspective dataset adds information to these mentions. It indicates the source of the mention, which can be someone who is quoted or someone who wrote or published the article that contains the statement. The database also indicates for each event mention whether the event was CERTAIN, PROBABLE or POSSIBLE, whether the truth value of the event is POS (it happened) or NEG (it didn’t happen) and whether the event took or takes place in the NON_FUTURE or whether it was a statement about the FUTURE.
This additional information allows us to compare information about the same persons or events coming from different sources. We can see where sources complement or contradict each other and hence compare the perspective they provide on an event, person or organisation.
Ask the NewsReader team about details if you want to use this model
The perspectives dataset can be accessed through a separate SPARQL end point: http://pvsge014.labs.vu.nl:8890/sparql (credentials will be provided during the hackathon)
Visualisation Tool: SynerScope
SynerScope is an interactive visual analytics platform that allows the user to explore all data in different views simultaneously. A selection made in one view is directly visible in all other views, making hypothesis testing and hypothesis finding fast and intuitive. Different data types are integrated in a single dashboard, whether structured or unstructured data, or data linked from external sources. During the hackathon, we will have a few machines available with the SynerScope tool and the Cars3 dataset installed for you to play with.
For the NewsReader project, we have loaded the output of the pipeline into SynerScope, creating views of the extracted event types and labels, such as the ESO relations; and the labels, types and descriptions of the entities. These views are combined with timeline views, a web loader connecting to the KnowledgeStore and a network view, connecting the different entities through their shared events. In this visual interface we can now query the data.
The following examples are taken from a subset of the data, focusing on Tesla Motors. If we want to know all the events in 2010, we can select the bar for 2010 in the top right view. This selection is directly propagated to all other views.
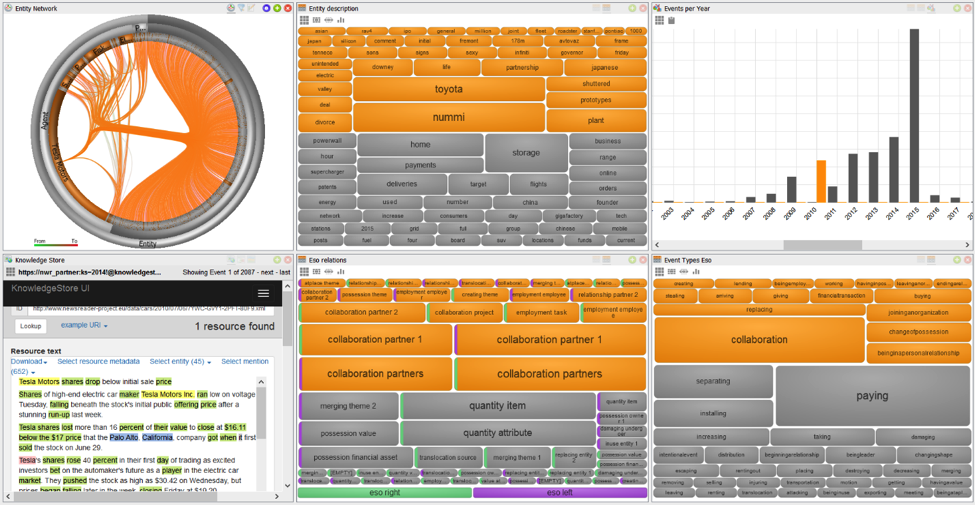
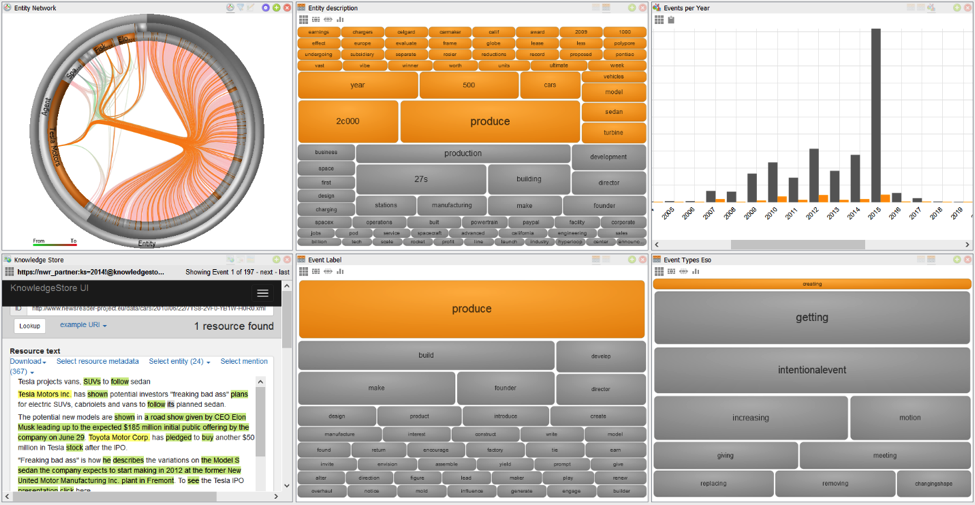
Another example of the same dataset shows how using SynerScope we can also build more complex visual queries. Here we have started by selecting all events with the ESO type “creating” and drilling down to this subset of the data. Next we select all events with the label “produce” to see what Tesla has produced (or is planning to produce). We notice in the timeline top right that the creating-events have a peak in 2015. And in the KnowledgeStore we can read that Tesla intends to produce vans and SUVs to follow their sedan model.
NewsReader Code
You can find the source code to the Natural Language Processing Modules and the KnowledgeStore at https://github.com/newsreader The modules are further described in Deliverable 4.2.2 Event Detection, but this document is only for those really interested in this part, as it;s pretty long. All other documentation on the project can be found on the Deliverables and Tech reports pages. But it’s probably easiest to ask a NewsReader team member.
Happy hacking!
2 comments